Output tabellen van de one sample t-test
Stap 1
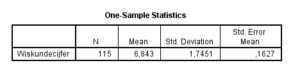
In de eerste tabel in de output van de one sample t-test worden de statistieken van de klas (complete dataset) gegeven. Hier staat simpelweg dat de klas uit 115 personen bestond, een gemiddelde had van 6,84, een SD had van 1,75 en een SE van ,16. Deze kan je later rapporteren bij het beschrijven van je resultaten, maar hoef je voor de test verder niks mee te doen.
De volgende tabel gaat je vertellen of het gemiddelde cijfer van de klas verschilt van 6.
Interpreteren output one sample t-test

Stap 2
Je hebt het gemiddelde van de klas (6,84) vergeleken met het gegeven gemiddelde 6 (staat in de tabel als test value). Het verschil tussen het gevonden gemiddelde en 6 vind je onder mean difference. Je wilt weten of dit verschil significant is. Dat wil zeggen dat we met 95% of meer zekerheid kunnen zeggen dat dit verschil bestaat. Dat is het geval als onder Sig. een waarde staat van ,05 (5% foutkans) of lager. In het voorbeeld staat onder Sig. een waarde van .000 (minder dan ,01% kans op een fout) dus kleiner dan ,05 (5% kans op een fout) dus mogen we zeggen dat er een (significant) verschil is tussen het gemiddelde van de klas en het gegeven gemiddelde.
Stap 3
In stap 2 hebben we bepaald dat er een verschil is tussen het gemiddelde de klas en het (gegeven) landelijk gemiddelde. We hadden 2 hypothesen namelijk de H0 en de HA. We moeten nu één van de twee verwerpen en de andere aannemen.
We waren voldoende overtuigd (met meer dan 95%) om de H0 te verwerpen en de HA aan te nemen omdat er verschil is tussen het gemiddelde van de klas en het (gegeven) landelijk gemiddelde.
Wat als je er niet uitkomt met de one sample t-test?
Kom je er niet uit met de one sample t-test? Check dan onze online spoedbegeleiding of wat we nog meer voor je kunnen betekenen!



